Zákon o umělé inteligenci (AI)
V Česku byl v roce 2024 přijat Zákon o umělé inteligenci (AI), který implementuje nařízení
Evropského parlamentu a Rady (EU) 2024/1689 (tzv. AI Act).
Tento zákon upravuje používání systémů umělé inteligence, stanovuje pravidla pro jejich vývoj,
nasazení a dohled, a to s ohledem na bezpečnost, transparentnost a ochranu základních práv.
Odkaz na zákon Akt o umělé inteligenci.
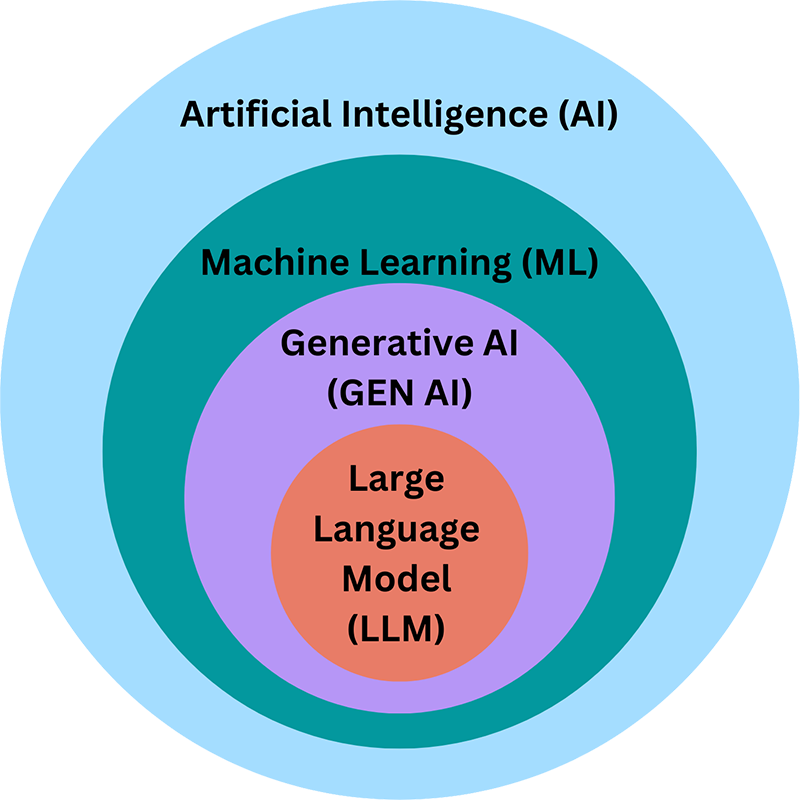
Co si představit pod pojmy:
široký soubor technik a systémů, které napodobují nebo podporují lidské kognitivní schopnosti (učení, rozhodování, rozpoznávání). Zahrnuje tradiční ML/AA, symbolické systémy, robotics, atd.
specifický typ AI modelu trénovaného na obrovských korpusech textových dat, aby generoval a zpracovával text, rozuměl kontextu, odpovídal na dotazy, tvořil souvislý text. Příklady: GPT-4, Claude, Llama, BERT (technicky spíše pre-trained transformer model), atd.
legislativní rámec EU, který reguluje vývoj, nasazení a prodej AI systémů.
Cíl: minimalizovat rizika, zajistit transparentnost, odpovědnost a ochranu práv občanů, a vytvořit jednotný evropský trh pro AI.
Jak spolu tyto tři systémy souvisejí?
Specifické výzvy pro LLM a generativní AI
- Halucinace a důvěryhodnost výstupů: LLM mohou generovat nereálné nebo nepřesné informace
- Bias a etika: tréninková data mohou odrážet společenské nerovnosti
- Bezpečnostní a zneužití: technologie může být zneužita k phishingu, deepfake, škodlivým aktivitám
- Souhlas a soukromí: použití dat při tréninku a během provozu musí respektovat práva jednotlivců
- Vymahatelnost odpovědnosti: kdo je za výstupy zodpovědný (tvůrce modelu, poskytovatel, uživatel) – definice v AI Act a smluvní ujednání
- Auditovatelnost a etické zásady: vyžaduje se registrace, záznamy, protokoly a ability k auditům.
- Srovnání s obecnými (foundation models): vysoký dopad na trh; vyžaduje standardy pro odpovědnost napříč různými použitími a licencí.
Proč je LLM zvláště rizikový v kontextu AI Act
Rozsah a povaha generativních výstupů
Široký dopad na práva a soukromí
Komplexnost a infrastruktura
Ovlivnění důvěry a legitimacy výstupů
Hlubší pohled na definice rizik podle AI Act v kontextu LLM
Nejde jen o samotný model, ale o to, jak je použit: např. diagnostika, náborová rozhodnutí, rozhodování ovlivňující práva, finanční posouzení, veřejná správa. Regulační požadavky se aktivují v závislosti na rizikovém profilu nasazení, nikoli jen na typu modelu.
Prohibice a omezeníNěkteré praktiky (např. manipulativní techniky, biometrii bez adekvátního watchdogu, zneužití pro masivní šíření dezinformací) mohou spadat do zakázaného prostoru. U LLMu může jít i o specifické aplikace, které využívají textové modely k vytváření přesvědčivých, ale falešných identit nebo klamavých prezentací.
Nedílné komponenty shodyShoda zahrnuje technické i organizační prvky: data governance, risk management, dokumentaci, post-market monitoring, a odpovědnost za výsledky.
I. Marketing a reklama
Personalizace a cílení reklamy
- Transparence: Pokud používáte AI pro personalizaci reklamy (např. na základě chování uživatelů), musíte uživatele jasně informovat, že je reklama generována nebo optimalizována pomocí AI.
- Souhlas uživatele: Podle GDPR musíte mít výslovný souhlas uživatele se zpracováním jeho dat pro marketingové účely. AI nesmí zpracovávat osobní údaje bez tohoto souhlasu.
- Zákaz manipulace: AI nesmí být použita k skrytému ovlivňování rozhodování uživatelů (např. pomocí deepfake videí nebo klamavých reklam).
Generování obsahu (články, texty, obrázky)
Označování AI-generovaného obsahu: Pokud používáte AI k generování článků, fotografií nebo jiného obsahu, musí být zřejmé, že jde o výstup umělé inteligence.
To platí zejména pro:- Fotografie: Pokud jsou generovány nebo upraveny AI (např. deepfake, syntetické obrázky), musí být označeny jako "AI-generované".
- Články a texty: Pokud je obsah generován AI, musí být čtenáři informováni (např. označením "Tento článek byl vytvořen pomocí umělé inteligence").

II. Ochrana dat
Fotografie a biometrická data
Zpracování fotografií: Pokud AI zpracovává fotografie (např. pro rozpoznávání tváří nebo analýzu emocí), musíte dodržovat GDPR:
- Souhlas: Musíte mít souhlas dotyčné osoby se zpracováním jejího obrazu.
- Minimalizace dat: Nesmíte shromažďovat více dat, než je nezbytně nutné.
- Právo na výmaz: Uživatelé mají právo požadovat smazání svých fotografií a dat.
Zákaz nekontrolovaného použití: Např. rozpoznávání tváří na veřejných místech je povoleno pouze za přísných podmínek (např. pro bezpečnostní účely).
Generování a úprava fotografií
- Deepfake a manipulace: Zákon zakazuje používání AI k vytváření deepfake fotografií nebo videí, která by mohla poškodit reputaci nebo klamat veřejnost.
- Autorská práva: Pokud AI generuje fotografie na základě existujících obrázků, musíte respektovat autorská práva původních autorů.
